
Table of Contents
*This post may contain affiliate links. As an Amazon Associate we earn from qualifying purchases.
The modern world runs on relational databases.
Today, we?ve thrown away all the manila folders and three-ring binders that once stored and organized information. Digital tools and database systems like Microsoft Excel, QuickBooks, and Customer Relationship Management (CRM) systems store information.
We?ve come to rely on computers to store data, but in the past, they were a little better than a piece of paper and a pencil. Modern computers, however, are much more efficient. We can type a query, swipe on a screen, or use a menu and instantly access information from almost anywhere in the world. In just a few brief moments, the data we need is at our fingertips. Near real-time access to facts and figures is not only possible but easy.
If you think about it, with the world wide web and instant access to information, we carry the sum of human knowledge in our pocket. We have relational databases to thank for that.
Let?s take a closer look at relational databases and where they came from. We?ll dive into how they work and what the future might hold for our data.
A History of the Relational Database

Image Source: Pixabay
For many of us, the database is the dull, boring center of the computer revolution that transformed our world.
But the digital revolution we are living today really started with data. As humans began accumulating and using data, we needed a better way of storing and accessing information.
Using data has really been the spark that ignited past revolutions in human knowledge. Whenever humans are faced with too much information, we?ve found a better way to organize it ? a data revolution. Written language, the printing press, and even newsprint are all leaps in technology that helped us better organize data. Punch cards and filing systems like the Dewey Decimal System are all database methodologies for connecting us to information.
That?s how the relational database helped unlock the digital revolution.
Flat Files and Early Computers
Before the relational database, early computers used a flat database to store information. Data was kept in a long and generally disorganized text file called a tab delimited file. Each entry in an early database was separated by a special character like a vertical bar.
An entry in a tab delimited file can contain multiple different pieces of information, or fields, about the object referenced in the database. As new information is added to the database, it is thrown into the text pile. That tab delimited file grows larger and more chaotic.
This large block of disorganized text makes it difficult to access specific data, especially for slow computers in the past. The format had little organization, making it difficult for any search function. A query could take significant time with unsure results.
Relational Databases and the Beginning of SQL
Edgar Codd, a young programmer at IBM?s San Jose Research Laboratory, wrote a paper called, ?A Relational Model of Data for Large Shared Data Banks,? in which he proposed the database could be better built for search functionality.
By organizing the data, the database format could be used to query the data to find connections. The database itself became a tool in the query function. The goal, according to Codd, would be to organize the data within the machine (or computer database) for searching and easy access. The paper presented a new navigational paradigm for computing.
In 1974, IBM created a prototype relational?? database called System R using Codd?s concepts. This database became the basis of the Structured Query Language (SQL) which was later commercialized by Oracle. Since then, SQL has become the most popular and commonly used bulk data storage system.
What Is a Relational Database?
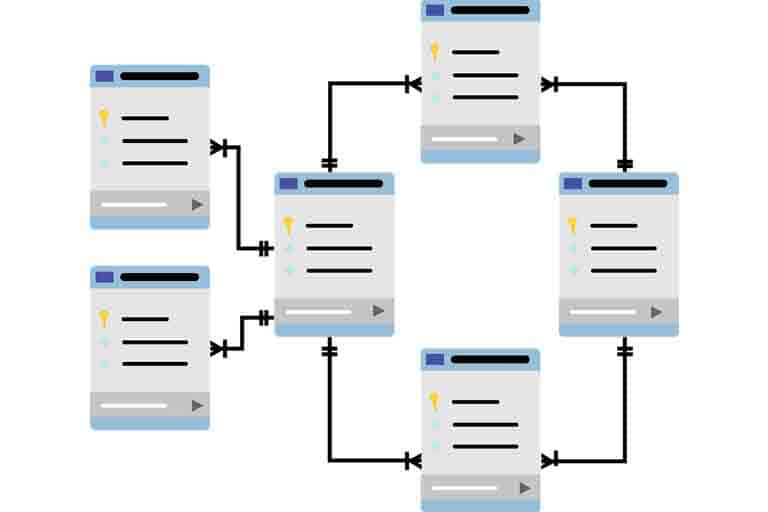
Image Source: Pixabay
Rather than use flat text files to collect and organize information, a relational dat??abase (RDB) stores data sets in tables, rows, and columns. This organization creates a defined relationship between the data in a row, a record, and a table.
Using Edgar Codd?s ideas, the RDB and SQL map the data in the tables, making it easy to organize, search, identify, and report on the data. You can quickly find specific information. Here?s how it works.
Building a Table in a Relational Database
Following Codd?s relational model, several terms are used to define and organize a table. The layout of a table includes:
- Row: Also known as a record or tuple, it is a specific piece of data representing a single item.
- Column: Also known as a field or an attribute, they represent the values attributed to a tuple, item or entity type.
- Table: Also known as a relation, it is a set of records or tuples that share attributes and is usually focused on an entity type.
For example, consider a relational database table in a CRM database. A table, or relation, might focus on customers. One column in that relation might contain the attribute Customer Name. Another column or attribute might contain Address, and another Email. One record, or tuple, in an attribute column might be the name John Doe, a specific customer in the CRM.
Keys in a Relational Database
An RDM also uses keys to establish the relationship between data and tables and can speed up search and query functionality.
A primary key (PK) is assigned to each table. Each row in a relation, or table, will also have a unique key assigned to it. Using keys, multiple rows, even between two different tables, can be linked together. With these keys in place, a column can be added to tables for a key attribute. Several columns, or attributes, can be linked together using alternate keys (AK).
Keys are used to show the relationship between tables and the data in the tables. With keys, connections can be made between the information in a database ? between tables and within attributes. Using keys, a system can more easily run queries to find specific data. Rather than searching through text files, a computer can quickly organize data using the keys and then do a targeted search on the smallest amount of data possible.
Other Methods of Organizing Data in Relational Databases
A relational database has a few other devices to organize the data, making it easier to search and access the data you want:
- Relationship Types: Database relationships determine the connection between tables. There are three types of relationships. The first is one-to-one, where the PK value connects to one, or no, data type in the connected table. The next is one-to-many, in which the PK value of one record could potentially connect to many records in the other table. Finally is many-to-many, in which there are multiple connections between the tables. In many-to-many relations, a third table will be used to link the tables.
- Domain: A relational database uses domain to identify the possible values for an attribute. When a domain is used, the system knows any attribute in a table will be limited by the domain. For example, a phone number will only contain an integer value.
- Constraints: With constraints, you can further restrict a domain, typically using business rules. For example, you could restrict the data in a tuple to an integer less than 100.
As you add domains and constraints to the database, the system can better organize and use the data helping to further increase efficiency.
A Final Word on the Relational Database

Image Source: Pix??abay
With the rise of Big ??Data and the Internet of Things (IoT), we?re on the edge of another data revolution.
Already, data scientists are looking at ways to better organize and use data, and that starts with the relational database. Even with faster processors and better storage, we need to more efficiently organize and access information.
Data experts have begun examining non-relational databases, also known as NoSQL, to meet a growing need in modern software applications. Many applications today, especially in the IoT field and in modern software development, generate massive amounts of unformatted and rapidly shifting data. Relational databases aren?t suited to managing data like this.
NoSQL database types include document store databases that link complex data to an object with key-value pairs known as a document to organize the data, rather than a table. Graph databases organize data as a network of objects to simplify data visualizations and analytics.
It?s an exciting time in data management, as Big Data is changing our world. In fact, an estimated two-and-a-half quintillion bytes of data are generated across the world every day. Technology like the relational database, and the new NoSQL database technologies, are unlocking the potential in the data and having a positive impact on our lives every day.
Featured Image Source: Pixabay